
AIP加速課題
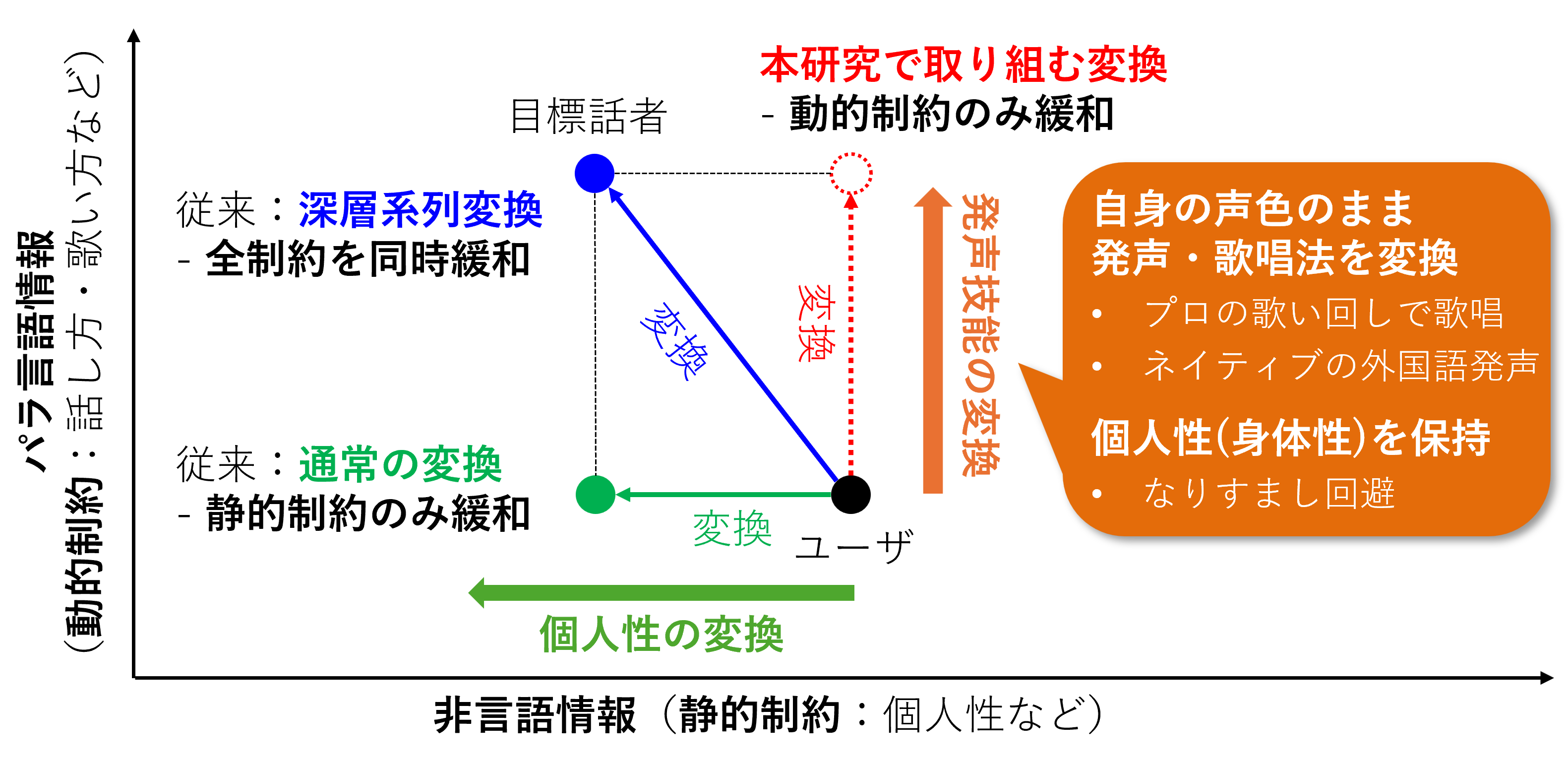
本プロジェクトでは、発声・歌唱技能を拡張した音声・歌声の生成の実現に向けて、より精密に所望の特徴のみを制御可能とする音声変換基盤技術の構築に取り組みます。非言語情報とパラ言語情報の独立制御を可能とし、非言語情報に相当する静的な制約(話者性)は保持しつつ、パラ言語情報に相当する動的な制約(発声表現・歌唱表現)を緩和可能とすることで、音声変換基盤技術を発声技能拡張基盤技術へと発展させます。従来の音声変換では、発声器官の変換、もしくは、発声器官と発声器官動作の同時変換が研究対象とされていましたが、本研究ではさらに発声器官動作のみの変換を実現することで、「音声変換=発声技能の変換」という新たな視点から新規研究分野を開拓し、国際的に本研究分野を主導する立場を確立することを目指します。
CREST研究課題
本プロジェクトでは、発声機能拡張グループ、聴覚機能拡張グループ、機械学習基盤グループの3グループを結成して、共創型音メディア機能拡張に関する研究課題に取り組みます。各グループが主に取り組む研究課題は、以下の通りです。
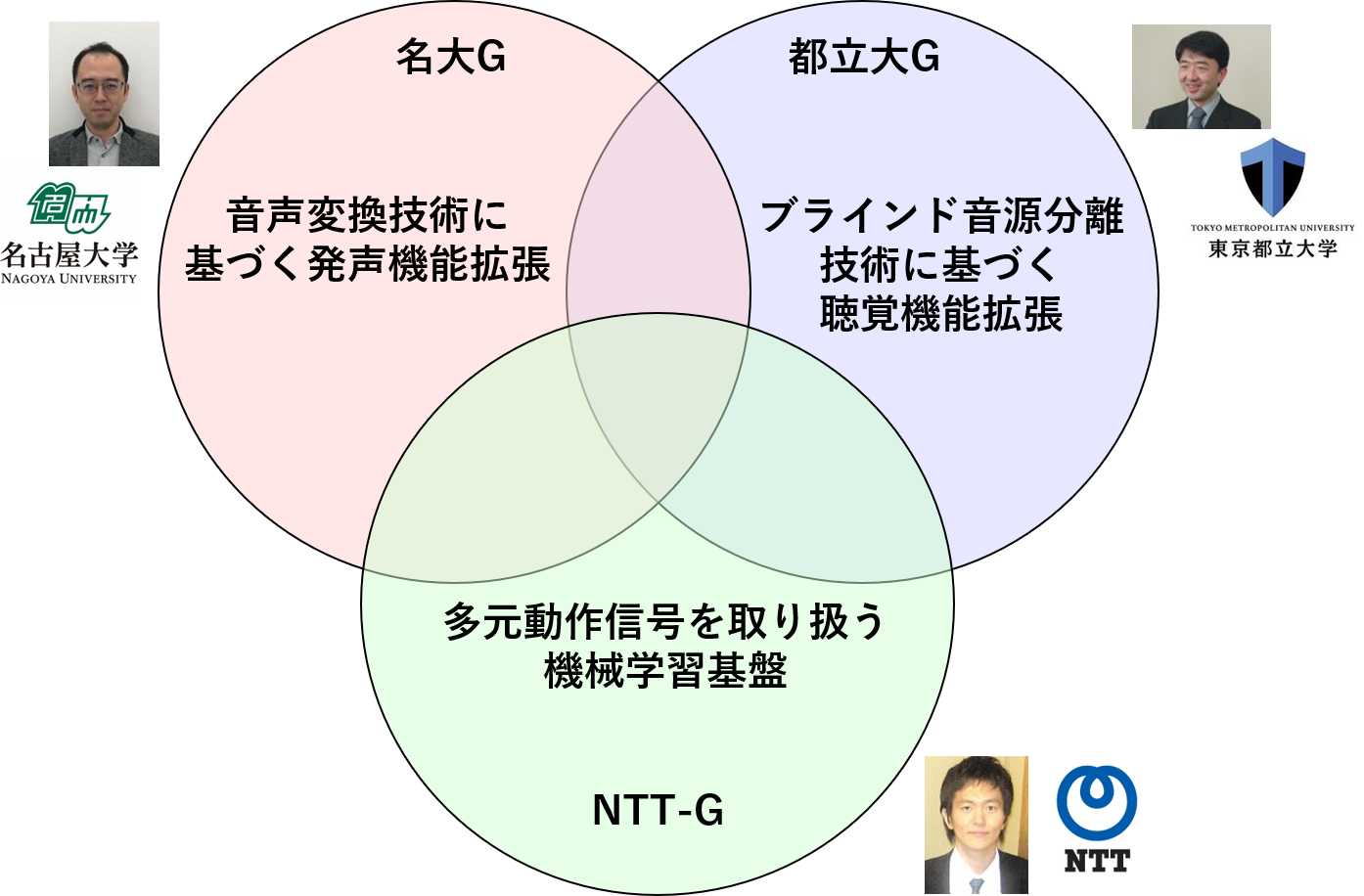
発声機能拡張グループ(名大G)
共創型発声機能拡張として、ユーザが発声した音声に対して、機械学習に基づく低遅延リアルタイム音声変換処理を施すことで、自身の身体的制約を超えた所望の音声による発声・歌唱を可能とする基盤技術の構築に取り組みます。また、応用技術として、発声障碍者の失われた発声・歌唱機能を回復する発声・歌唱支援システムや、健常者の発声・歌唱能力を増強するシステムの構築に取り組みます。
これらのシステムを身体機能の一部として利用可能とするためには、出力音声や歌声の表情(声質、抑揚、感情表現、歌唱表現など)を、ユーザの意図した通りに動的に制御する仕組みが必要となります。しかしながら、例えば、発声障碍者による音声・歌声は、身体的制約の影響により、これらの情報が大きく欠落したものとなるため、ユーザが意図する音声・歌声表現を推定すること自体が本質的に困難となります。そこで、音声・歌声のみならず、発声時に伴う多元動作信号(マルチモーダル動作信号)も併用することで、システムの挙動を意識的に制御する技術を実現するとともに、ユーザとシステムのインタラクションを促す仕組みを導入することで、ユーザの意図したシステム挙動を達成する共創型発声機能拡張技術を創出します。
聴覚機能拡張グループ(都立大G)
共創型聴覚機能拡張技術として、聴こえる音を低遅延リアルタイムに処理して提示することにより、聴覚機能が低下しているユーザの聴こえを補い、また健聴者の聴覚機能を増強する技術基盤の確立に取り組みます。
補聴における長年の課題の一つは聞きたい音だけを増幅してユーザに提示することであり、単純な音の増幅は雑音をも増幅してしまい、ユーザの聴こえをむしろ阻害してしまうことが以前から指摘されていました。近年、高度に発展したブラインド音源分離技術は、音源位置や方向に関する事前情報を全く使わずに混合音を分離できる優れた利点をもつ技術であり、補聴への応用も大いに期待されていますが、ブラインド処理であるが故に分離した複数信号のどれがユーザの聞きたい音であるかわからないという本質的な問題があります。また、現在の音響信号処理の多くは、計算効率性、物理的解釈の容易さ、モデル構築のしやすさなどから時間周波数領域で行われていますが、信号を1フレーム(数十~数百ミリ秒)分蓄積してから周波数領域に展開する必要があるため、どうしても1フレーム分の遅延が生じます。そこで、ブラインド音源分離技術を聴覚機能の拡張に活用するために、ユーザとのインタラクションを活用する低遅延リアルタイム音源分離技術を創出します。
機械学習基盤グループ(NTT-G)
発声機能拡張技術と聴覚機能拡張技術におけるシステムの挙動を、ユーザがシステムとのインタラクションを通じて自在に制御できるようにするための機械学習基盤の構築に取り組みます。
機器操作、視線、ジェスチャ、顔表情などの動作信号に含まれるユーザの制御意図を正しく認識し、システムがとるべき挙動に適切に反映するために、動作信号と制御対象の物理量を正確に結びつける基盤技術を創出します。また、ユーザによるシステムの一方向的な制御だけでなく、システムの利用を通じ、ユーザとシステムが互いの振る舞いや傾向を協調的に学習し合い、ユーザが感じうる感覚のギャップを自律的に埋められるようにする方法論の構築に取り組みます。さらに、ユーザがシステムを安心して利用できるようにするため、システムの安全性を保証する基盤技術を創出します。